
When Batch Normalization Hurts Performance

Batch normalization1 is a tried and tested method for improving the performance of machine learning models. I demonstrate that in certain scenarios, it significantly hurts performance instead, and this occurrence is not limited to small batch sizes.
In the group normalization paper2, it is shown that a batch size of under 16 is ineffective for ImageNet3 classification, and the challenges of applying batch norm to recurrent models is detailed in the layer normalization paper4. However, the technique is generally considered safe as long as the batch size is not very small.
I demonstrate experimentally that for certain scenarios, the batch sizes required to make batch norm improve baseline performance are impractically large. The code for the experiments is available on my Github.
Classification
This is the context in which batch norm was originally introduced, and there are no issues here.
To test the approach on a simple classification problem, I chose the CIFAR105 dataset. I normalize the data range to [-1,1] and I apply random horizontal flips and random shifts to the image to augment the training dataset. The task of the model is to correctly assign one of the 10 class labels to each input image. You can check all the hyperparameters in the source repository.
I use the following PyTorch model for the classification test:

The type of the normalizing layer can be either nn.BatchNorm2d or nn.Identity, which is a no-op. I use cross-entropy loss to train the classifiers.
I get the following results after training the models for a hundred epochs:

Without batch norm, the test accuracy is 0.7989, and with batch norm it is 0.8125. Clearly, batch norm does its job here.
Autoencoding
In contrast to classification, autoencoding gives batch norm a hard time. This is the experiment model:

I use a wider network here because overfitting is not a problem at these model sizes. The architecture of the encoder part is otherwise the same as in the previous case, and it is mirrored as a decoder using transposed convolutions. I use mean squared error to train the autoencoders.
Here is the outcome:
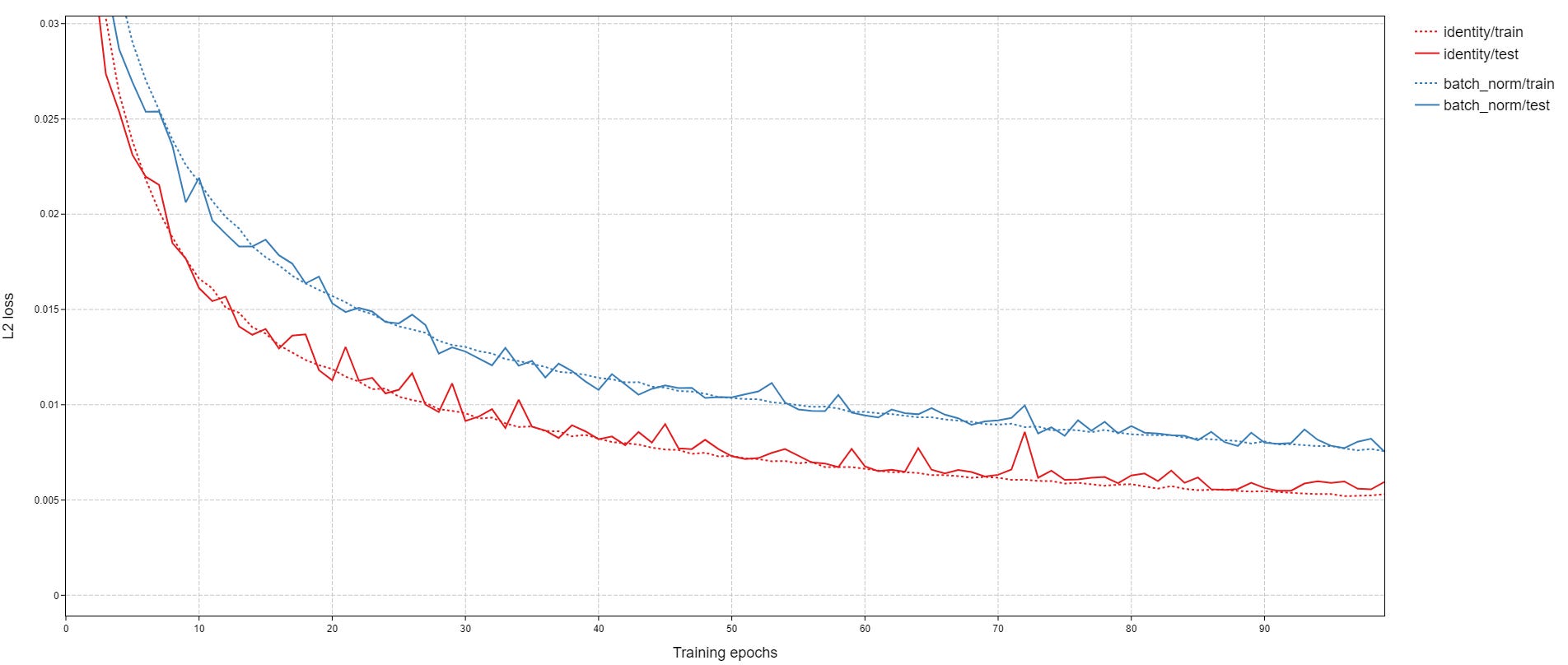
The model without batch norm does significantly better: it learns faster and it has a better final performance. Without batch norm, I get an final test L2 loss of 0.005948, and with batch norm I get 0.007543. Although the trainings could be run for longer for better performance, this doesn’t change the relative outcomes in my experience.
Treating the square roots of the final losses as distances, we can say that the distance from the target is 12.61% larger with batch norm:
>>> math.sqrt(0.007543) / math.sqrt(0.005948)
1.1261249325984088The likely cause of the bad performance of batch norm in this case is that a lot of information has to pass through the network for a successful reconstruction. Image classification is a type of lossy compression, and it is very lossy: the output is just a label. Autoencoding performance degrades quickly with loss of information, however. Because of this, the noise injected by batch norm outweighs the technique’s benefits and the result is worse performance.
To test this hypothesis, I ran the trainings with an increased batch size of 512:

The results are closer this time, but the identity norm is still better. Going from a batch size of 512 to 2000 (I wanted batch_size % train_set_size == 0 at this size) finally puts batch norm in the lead:

Because I kept the learning rate and number of epochs constant however, higher batch sizes resulted in worse performance:

All trainings had roughly the same time cost on my PC:

I tried raising the learning rate for batch size = 2000 to see if I can speed up learning without making the trainings longer. While this worked to some extent with batch norm (training destabilized without), learning rates over 1e-3 caused increasingly more overfitting. In the end, these attempts didn’t even reach batch size = 512 levels:
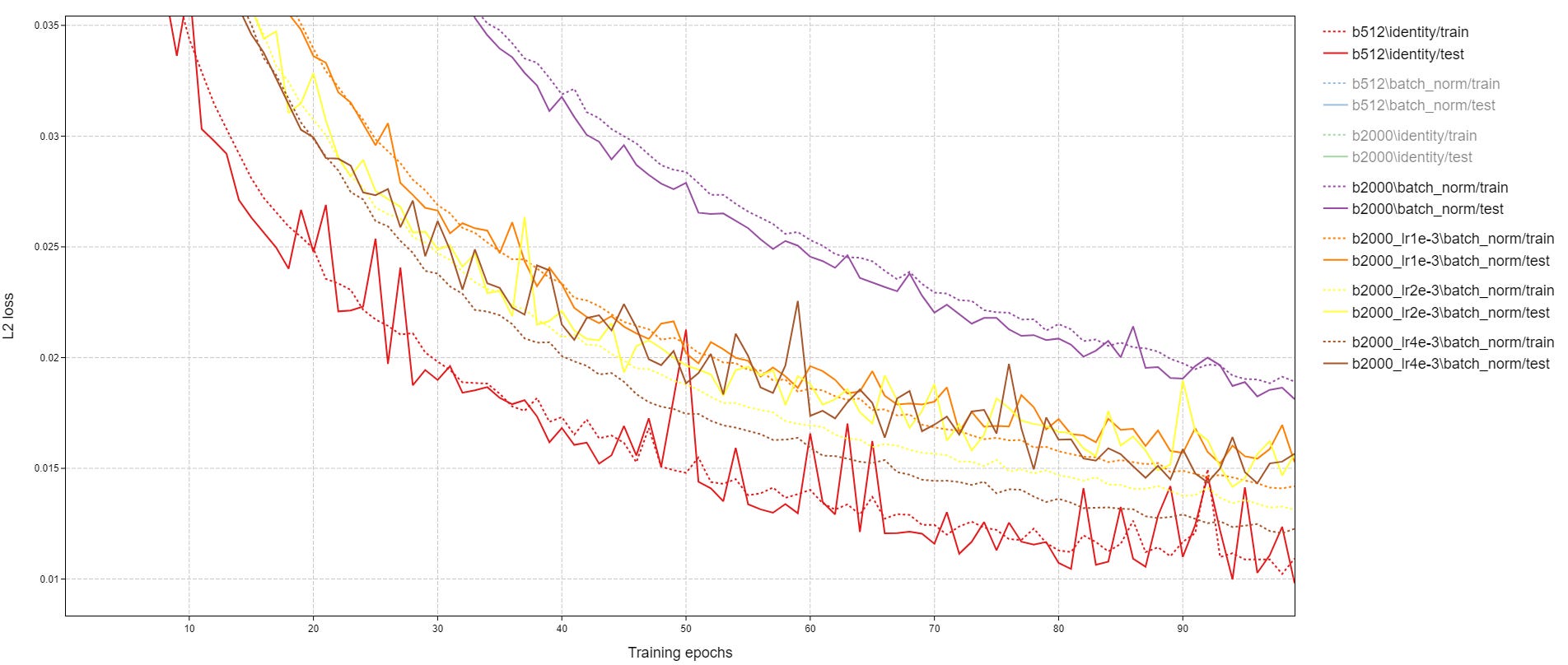
In conclusion, making autoencoding work with batch norm is a tough cookie. It is worth considering alternatives. Layer norm works well in my experience. I will leave the details of that for another time.